
[tech] Consistency models for service data
[tech] Consistency models for service data

Context
Most software services deal with data, storing and retrieving it as needed. However, ensuring this data remains consistent can be challenging. There are many options on how data can be accessed after being written based on various architecture tradeoffs. This complexity is further exacerbated in distributed systems spread across multiple data centers. This article discusses the complexities of data consistency in such systems and offers solutions to navigate them effectively. This topic is broad and if there are areas that I’ve missed, getting feedback will help immensely.
Let’s consider a service as a logical concept which is composed of a deployment of multiple stateless compute nodes and private stateful datastores. We explore single region and multiple region deployment scenarios.
Consistency Models

There are three main consistency models for service data-
Weak consistency: These services are optimized for high throughput, low latency operations with some permitted data loss or reordering. Services that store click streams, log data, metrics or high volume events in parallel are some potential examples. When reading the data, there can be stale reads if some processing is partially delayed.In software design, there's a trade-off between consistency, availability, and partition tolerance (known as the CAP theorem). Let’s consider the CAP theorem as a spectrum of choice from Availability to Consistency since partition tolerance is not configurable. These services are heavily biased towards high availability and sacrifice consistency.
Eventual consistency: Data in these services can diverge for some time (usually a few seconds) under normal operating conditions. Assume that an entity version v1 is stored at time t0. It might be possible that at a later time t1, on querying the service the request falls on a different internal node and you get a previous version of the entity. It is expected that within a short time interval all internal nodes within the service will catch up on the latest value of the entity. Hence the name - eventually consistent.Clients should be fine with a slightly inaccurate view of the data. Some patterns like caching on the writing session or client make at least the writer get a consistent view of the data just written while other clients reading will catch up (see session consistency). Data in this model is typically not lost, and repair mechanisms need to be set up to merge data for a consistent view. Caches might be used in the read paths which lead to inconsistent data for some time.On the CAP spectrum, this model favors availability slightly.
Strong or strict consistency: Data in these services appears consistent. A read after a write should show the last value written. Data for the system as a whole is typically split across shards or partitions and hence consistency can be scoped based on keys or customers or some dimension.This data would be part of some critical infrastructure or business requirement.On the CAP spectrum, this model favors consistency with an acceptable loss of availability.
These 3 categories can be further split into sub-categories based on specific data consistency needs. Most of the services I’ve built have used the eventual consistency model.
When you build modern Saas applications based on independent microservices owning their own view of the data; you are forced with eventual consistency for feature requirements that span multiple services anyways.
In large systems you might also need to support different data types with a mix of requirements. For example, control plane information like sharding information might need a consistent view while data plane information for entity information can be eventually consistent. Hence you can see different models being used in complex systems with differential consistency and availability guarantees.
Ultimately having a good understanding of your requirements is essential in making the right tradeoffs.
Now let’s dive into some advanced patterns for eventually consistent and stricter consistent services.
Designing Eventually consistent services
Region local consistency guarantees
Let’s consider a service that is using AWS DynamoDB as a datastore. Like many modern NoSql datastores, DynamoDb provides tunable consistency. Write operations are durable and will eventually sync across all internal data nodes. During reads, you can read stale or consistent values based on the read consistency parameter. However, this consistent view is limited to a single region.
DynamoDB tables can be configured to work across multiple regions with automatic data replication. There is no way to get a consistent view or configure a transaction across multiple regions. Hence a service deployed across multiple regions with replication configured will need to be eventually consistent. The gain is higher availability. Similar patterns apply to SQL database deployments.
Repair mechanisms
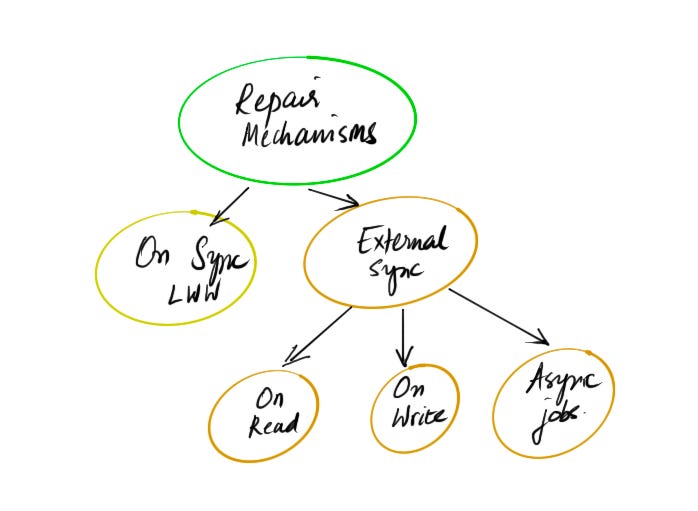
Since it is possible to write two versions of the same entity in different regions, during replication DynamoDb merges changes via conflict resolution. Conflict resolution in DynamoDB is at item scope (single entity defined by key). A last writer wins (LWW) reconciliation strategy between concurrent updates is used, in which DynamoDB makes a best effort to determine the last writer. Designing APIs to make sure that you do not end up with partial inconsistent data within an item because of how data can be merged is important.
CosmosDb from Azure, provides LWW and also custom policies for data reconciliation. I do not have practical experience with this tool though.
Services that depend on data from other services might be out of sync from the latest changes. Typically the source service emits an event stream with changes which can be used to fix the data in dependent services. Other alternatives are-
Data access based repair. When information is accessed, you can repair data based on some external system but otherwise leave stale data on disk.
Sync data on read of the entity with latest state
Sync data on write of the entity with latest state
Run background jobs to automatically repair data in the background independent of access to data. These scans are costly to run in large systems.
Designing Strong/strict consistent services
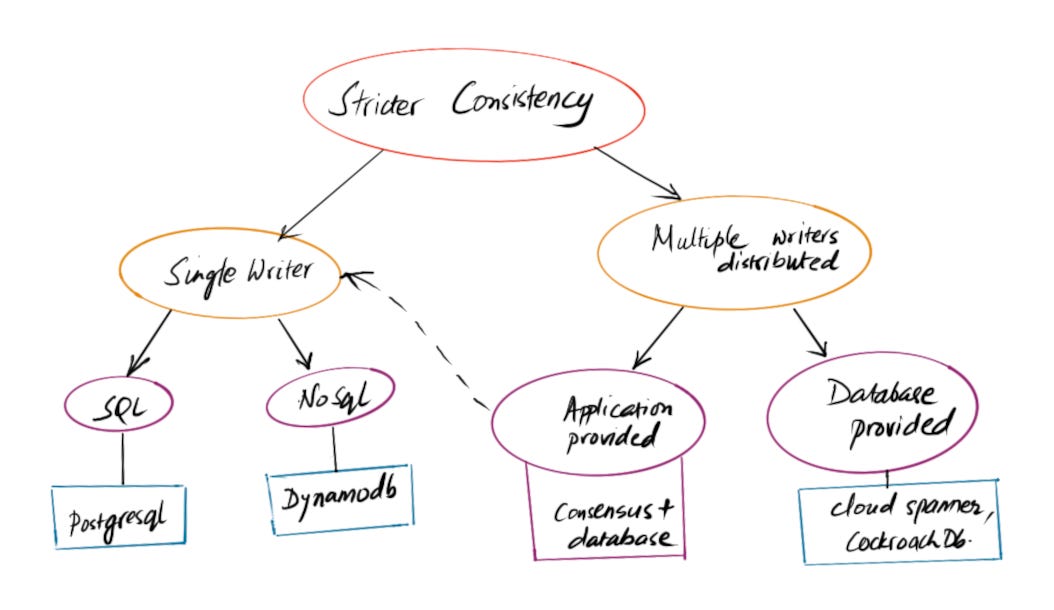
Single writer
Many services do not actually have active multi-region high-availability requirements. Hence operating in a single region with a local datastore is feasible and also cost effective. In such scenarios you can use SQL stores or even NoSql stores like DynamoDb and achieve consistent writes and hence service level consistency.
An alternative deployment is an active-passive deployment where the passive region acts as a standby. The active region is always replicating data to the standby. On a disaster event, you can change the passive deployment to be the active one. In an active-passive configuration only one region is the source-of-truth at a time. Region failure is derisked with this tradeoff.
Take a detour to read about dataomic which is a database that uses the similar single writer model (transactors) to provide immutable views of data.
Multi-region writers
At a large scale and a global footprint of clients, supporting multi-region writers typically becomes a requirement. The two patterns that allow for multiple distributed writes is Application layer provided or Database provided.
Application layer provided design takes database sharding ideas to the application layer. A service deployed globally will split stored data into different owned service shards. Let’s assume that a single customer can be mapped to a single designated write region. The service needs to maintain a routing table with strict consistency per customer data subset. Consensus systems like etcd can be used to maintain the routing information across all service shards. Large scale customer data can then be stored in service shards where they are consistent. Multiple independent service shards can independently write across the globe. During disaster events you end up with partial loss of availability. This model also helps with enterprise requirements like data locality.
Database provided consistency is possible with some solutions like google cloud spanner. Spanner effectively promises a consistent-available global store with “external consistency”. I’ve not used this product either but availability of such a platform component should highly simplify complex services.
References
CAP theorem and the extension PACELC theorem
Database Consistency Models with formal definitions
DynamoDb consistency conflict resolution
Consistency level choices in Azure Cosmos Db
Google Spanner consistency and Transactions