
Redefining Amazon DynamoDB


What is Amazon DynamoDB?
Let’s start by looking at the description of DynamoDB from the AWS developer guide.
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability.
The developer guide then expands into features like managed services, encryption at rest, backups, ttl, scaling and availability. Let’s revisit this description from the perspective of a distributed systems developer.
Amazon DynamoDB is a managed service that provides a distributed hash table that is indexable, heterogeneous, durable, available, eventually consistent, observable and replicable.
Now that’s quite a buzz wordy definition so let’s deconstruct the parts. Along the way we will get a sense of advanced features and patterns supported by DynamoDB.
If you already know about the basics of DynamoDB and are in a rush, search for patterns in this post and have a look at the Heterogeneous section which covers advanced topics.
Managed Service
DynamoDB is a proprietary SaaS system by AWS.
The data plane API is a key-value store over HTTP with multiple language SDKs available for ease of use. There are also multiple interface options.
Configuration via the control-plane or administrative API is possible but there are almost no administrative functions like a traditional database.
Internally DynamoDB is a massively distributed application continuously adapting to failures and dynamically scaling with load. Database services like RDS are also managed, but do require active maintenance like version upgrades. DynamoDB was built for the cloud and is relatively maintenance free.
Distributed Hash Table
Like a Hash Table DynamoDB associates keys to values (or data) stored on multiple distributed computers (partitions) and hence acts like a Distributed Hash Table. The hash of the key is used to decide which partition the data is stored in.
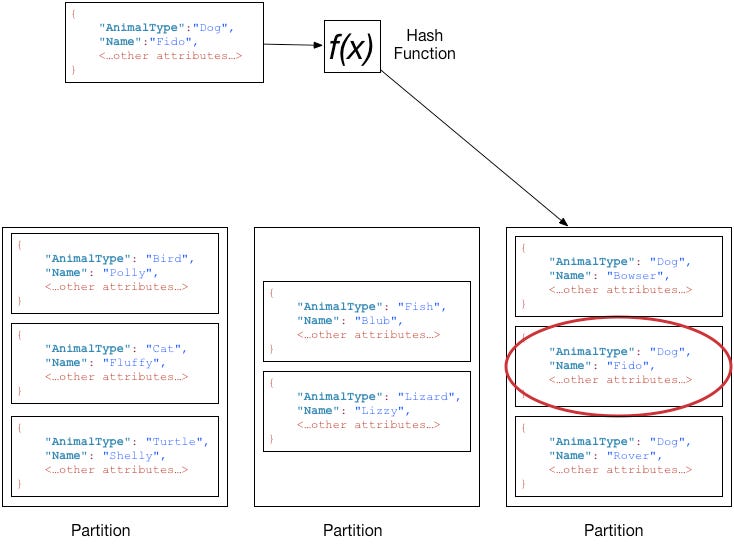
DynamoDB supports two types of keys
Partition key - When the partition key is used by itself, each partition key is used to address a single item or value. A value can have other fields and values including scalar, document and scalar types.
Composite key (Partition and Sort Key combination) - The composite key is used to uniquely address an item. The partition key is used to determine the partition where the item should be present. In addition, other items with the same partition key will be stored physically close sorted by the sort key.
DynamoDB is performant if the data-access patterns are uniform based on the logical keys for the data.
Like a Hash Table, lookup is efficient only if done via key. Data can be fetched directly from the partition that stores the item. This is the primary reason that DynamoDB can promise very fast performance even when the scale of the data grows to extremely large scale. Conversely scanning for all the data without a key lookup is not recommended and is expensive. Alternative searches are covered in the semi-indexable section below.
With sort keys, it is also possible to do efficient lookups of related items via range queries with conditions like ‘begins_with’, ‘between’, ‘>’, ‘<‘. This enables advanced data modeling patterns-
One-to-many relationships - Let’s take an example where a person (one primary) entity has addresses (many secondaries). The partition key is the id of the primary object or person. The information about the primary object can be stored using a fixed sort key like ‘person-$personid’. The many relationships can be addressed using the secondary object ids in the sort-key like ‘address-$addressid’.
It is possible to get details on a person by id and static sort key. It is also possible to get all addresses for a person by querying by sort key ‘begins-with’ address or a single address if the id is known.Version Control - current version can be stored with the sort key ‘v0’. Other versions (new or old) can be stored with other ‘v$X’ numbers. Using transactions, it is possible to keep data in sync. Read more about the version control pattern here. Transactions in DynamoDB are possible for write and read operations over multiple items and tables with the same region and AWS account.
Hierarchical relationships - Imagine a listing of geographic locations stored in the sort key like ‘#$country#$state#$city’. To search for all values in a state, the query would be the partition key and begins_with ‘#$country#$state’. For all items in the country search for ‘#$country’. Time ranges can also be considered to be hierarchical like order dates for a customer with year, month, day etc stored as Strings in the ISO-8601 format.
Indexable
DynamoDB allows secondary indexes to be created for the base table with different keys (partition and sort key) for alternative efficient queries. The core access pattern in dynamoDB is still the hash table but the keys that can be specified are different. The two types of indexes are-
Global Secondary Index - Different attributes from the data can be used for a partition and sort key. The GSI view of the data is stored in a different partition from the base table which means that the data is copied. It is possible to copy only keys, specific attributes or even the entire data.
Data from the base table is replicated (updated, or deleted) from the GSI asynchronously and changes will be eventually visible to clients.
It is possible to create upto 20 GSIs (this used to be just 5) as a default.
Local Secondary Index - The partition key for a LSI should be the same as the base table. The sort key can be based on a different attribute. There are data limits per partition key values.
It is possible to create upto 5 LSIs by default.
Working with indexes describes the differences between both indexes in detail.
Indexes unlock a new set of patterns.
Query based on different keys. This is the simplest usage of indexes.
Sparse Indexes - A index can be defined for an attribute that is present only for some items in the table. That means that querying the index will only return a subset of data from the entire base table. See an example for more details.
I’ll be covering more advanced patterns based on indexes below.
Heterogeneous
Tables, Items and attributes are core components in DynamoDB. A table is a collection of data items. An item is an identifiable (via key) group of attributes. Attributes are named properties that can be nested as well.
With traditional databases, a table is used for persistence of a single entity. Columns have values and additional constraints for the entity. DynamoDB is schemaless other than the requirements of the key. A single DynamoDB table can be used to store data about multiple heterogeneous entities and attributes can be different per item.
A single DynamoDB table can be used to store data about multiple heterogeneous entities
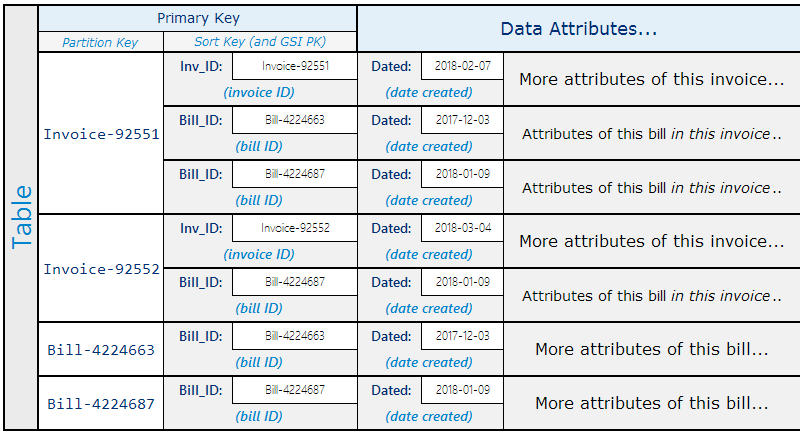
In the diagram above, we have a single table that can be used for the Invoice and Bill entities with a bi-directional one-to-many relationship.
An invoice can have multiple bills. Each invoice has some attributes and each bill in an invoice can have some invoice specific attributes.
A bill can be looked up directly and has its own attributes.
For a single entity usage, it is recommended to use good naming conventions for the keys (and index attributes) like personId. However, heterogeneous entities should use generic attribute names like pk, sk, gs1pk, gs1sk (the partition key and sort key for the first global secondary index). The type of the entity should be used as a prefix in the value of the attribute.
For advanced patterns that are possible see-
Many-to-Many relationship modeling using the Adjacency list pattern
GSI overloading - As explained above, different entities use the same generic attribute name so that a single GSI can be used for different searches. The application data access layer should have the knowledge to map from the data-layer attributes to the application layer models.
The 2018 re:invent tech talk on Advanced Design Patterns for DynamoDB is a great reference if you want to look at multiple examples of modeling with DynamoDB. That talk is in my top tech talks list!
Durable
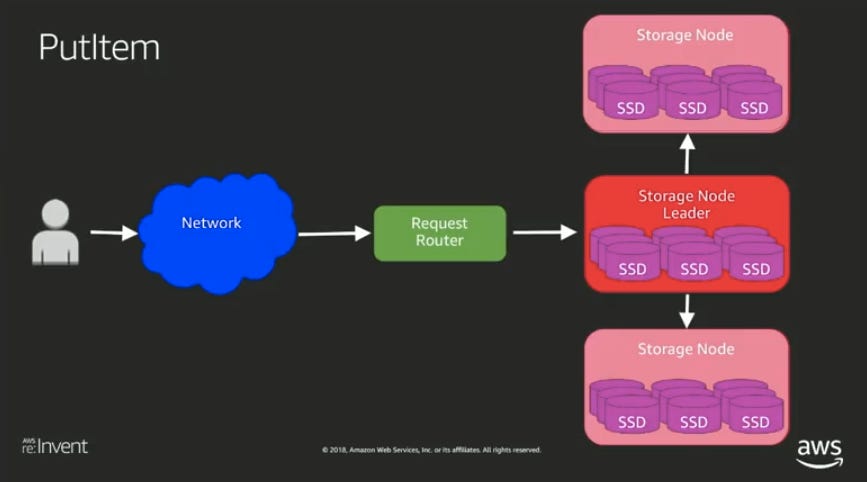
Data in DynamoDB is replicated internally to multiple hosts. The AWS tech talk “Under the hood” explains internals of the architecture and implementation of DynamoDB. Data is stored in Storage Nodes. For each partition key a specific Storage node is selected as the Leader node based on the Paxos algorithm. Writes are accepted by the leader storage node which should have all the previous changes for the key and then replicated to other Storage nodes.
A DynamoDB table is configured in a single region and the hosts that persist the data would be spread across AZs in the region for redundancy.
I’ll cover Global tables in the Replicable section.
Available
DynamoDB is an AP system based on the CAP theorem.
Different operations will have different availability. Although the original Dynamo paper goes into a quorum based available architecture, that design has evolved as described in the “Under the hood” talk. Write operations need selection of a leader node. Transactions, conditional updates would also some sort of advanced syncing. Read operations can be configured to be based on data from any node and slightly stale.
Global tables (Replicable section) enhance availability across regions.
Eventually Consistent (Reads)
DynamoDB supports eventually consistent and strongly consistent reads for read-after-write semantics for items. However features like GSIs and global tables are async and are always going to be eventually consistent since they are based on copying of data. Hence overall a system based on DynamoDB is going to be eventually consistent.
Transactions do offer stronger guarantees for writes and reads of data if needed. Transactions in DynamoDB are do have limitations compared to traditional ACID databases.
Observable
Streams publish a changelog of items as mutations in the table occur. It is possible to react to these changes via Kinesis or DynamoDB streams.
With DynamoDB streams it is possible to configure what changes you want to see as they happen - keys only, new data, old data, new and old data. I wonder why a new concept of streams was introduced instead of a SQS queue!
Streams allow for the data changes to be visible as a pipeline and new patterns for real-time processing are possible.
Aggregation - Data can be aggregated based on some time interval since the stream has a timestamp of when the change happened. Using this pattern counters can be updated as changes happen without needing to calculate the data in the application layer via queries.
Using lambda, custom processing for data conditions can be implemented.
External Integrations can be set up on change events like sending notifications.
Replicable
Global tables make DynamoDB multi-region and multi-active. Changes from one region are replicated to another automatically. This allows for low-latency access to data from across the world. It is possible to configure which regions a table will be replicated to via control plane APIs.
With sync across regions, the probability of conflicts due to different versions of data rises. DynamoDB uses a last writer wins strategy for conflict resolution based on vector clocks and versioning of each object. If two clients modify different attributes in the same item concurrently, both changes will be merged. However specifics for this merge behavior has not been documented.
In the original Dynamo (internal DynamoDB) paper, clients are given multiple versions of the data and can decide on a merge strategy. That API has not been exposed for DynamoDB. App sync which is based on DynamoDB offers custom conflict detection but I have not yet spent time understanding the service.
Applications
Using DynamoDB requires upfront design, understanding data and query patterns so that they can be modeled correctly. Data needs to be copied rather than denormalized.
DynamoDB is my preferred storage service for microservices in AWS in spite of these additional constraints. They actually force better requirements and design while providing simpler operations. It also serves as a crucial smell test - If a microservice needs to use more than a single table (heterogeneous entities obviously) is it of a right size or doing too much?
References
“Under the hood” talk has information about how the current DynamoDB system is architected.
Original Dynamo paper has technical details about how the core features were implemented earlier but is mostly out of date.
Thanks to Bruno Sales and anonymous for reading drafts of this.
Change log
Mar 14 - First published version
Mar 16 - Added references to “Under the hood” talk and updated information related to the dynamo paper.