Past, Present and Future of Server-Side programming
Past, Present and Future of Server-Side programming

Let’s look at how server-side programming has changed over the past two decades from the perspective of an Application developer. I’ll make some generalizations in this post, mix some concepts and my timelines are also indicative .. not precise. However the broad themes that I want to highlight should still be insightful.
My past, present and future classifications are also based on my rough estimates. I’m trying to consider the point when a technology reaches the “early majority” stage according to the technology adoption life cycle and chasm.
Computing Eras
Past - Dedicated Server Hosting
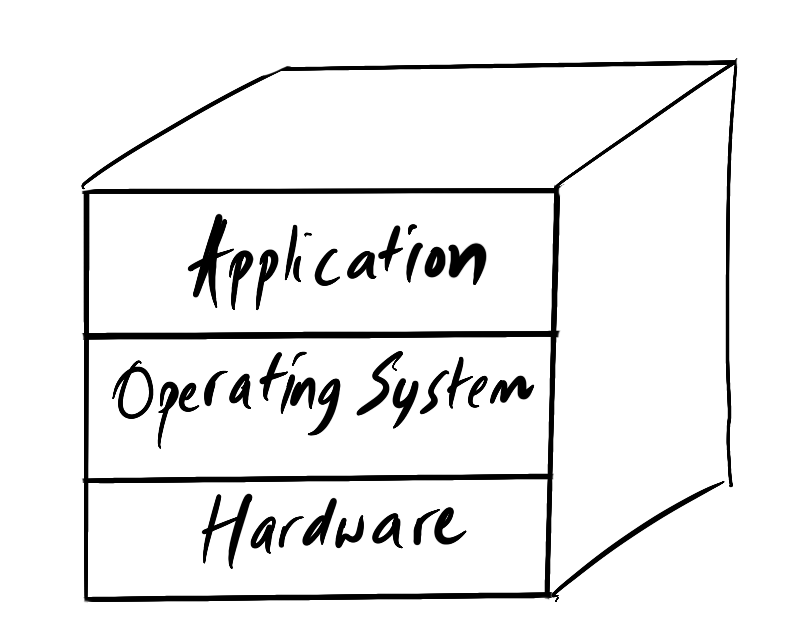
Let’s start this journey around the late 1990s to early 2000s. Hardware would be set up to run server software for a single application. The fantastic book about the early days of Netflix - “That will never work” by Marc Randolph explains how involved setting up a website was!
We bought dozens of Dells online and had them shipped to the office. We bought our own servers—in 1997, there was no shared cloud—and installed them in the corner. We bought miles of cable, and wired the office after-hours, ourselves.
At a mid to later stage of this era, larger companies would build and operate private data centers. Smaller companies would lease racks within data centers.
From an application developer's perspective, you needed to help make choices about hardware, maintaining operating systems and finally building your application.
Procurement of hardware required extensive planning and was a massive CAPEX cost. If you wanted to scale more, turn around time would be in order of weeks. Finance would authorize purchase of hardware, after that you get a shipment of physical hardware, someone would wire the new box into the rack. The control pane was possibly either physically installing software, booting over network, or out-of-band management software .. and after that you got to deploy your software. Appliances would be bought for scaling of specialized operations like load balancers and storage.
It was important to write applications that could run for multiple days without failure. Extensive manual testing was done before a deployment was made to production.
Although this sounds pretty archaic today, this period was a great advancement from the previous state. This model offers great control over the entire hardware and software stack.
Past - Virtual Machines
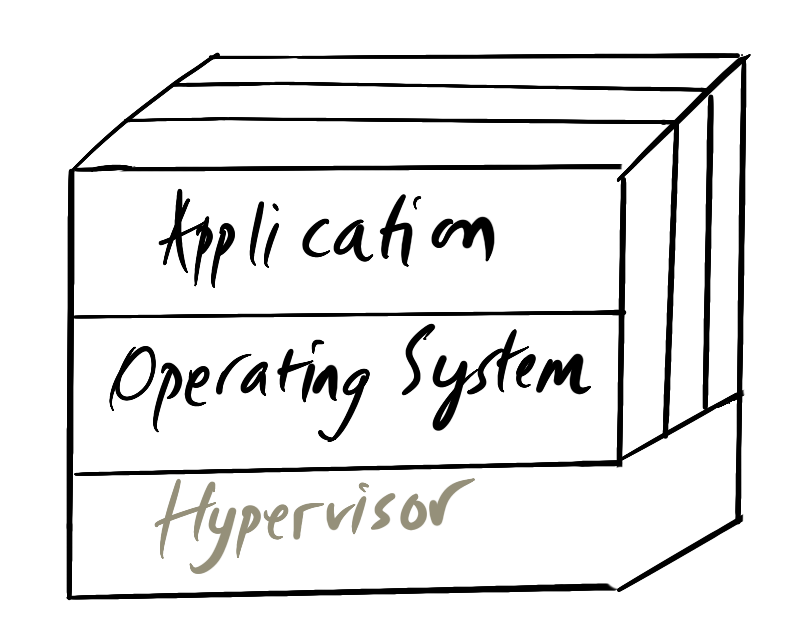
vmware was founded in late 1998 and entered the server market in 2001. It brought virtualization technology to the industry. With hypervisors, an actual physical machine has a host operating system and it can run one or more guest operating systems inside it. The guest operating system sees virtual hardware (processors, network, storage) and application processes run inside. Hypervisors provide security isolation between the different guest operating systems.
With virtual machines, the actual hardware became irrelevant for application developers. As long as there was virtual machine capacity in the data center, it was possible to deploy new applications.
Businesses also got massive cost savings because it was possible to over-provision software with virtualization. Even though there might be only 2 GB real RAM, it was possible to create virtual machines with say 6 GB. Actual load is mostly lower than expected load and hence this simple idea works. Estimates will always be fuzzy irrespective of any era!
Estimates will always be fuzzy irrespective of any era!
At a later stage technologies like vmotion helped apps to migrate across real hosts while applications were still in running state, allowing even more flexibility.
The datacenter still existed, but application changes now take only a few days to be deployed since the control pane now shifts to virtualization management software. A reboot of the operating system and initialization of the application might take some hours. Selling software to be installed in a customer's data-center still meant that upgrades and changes would not happen frequently and hence extensive manual testing was done.
Past - Cloud Monoliths

We’re now in 2006 with launch of AWS EC2.
Cloud computing took ideas from virtualization and instead of your own data-center you would trust AWS to run your software. We’re just considering EC2 here, which can be considered as hypervisors at scale.
The important aspect was not virtual machines, but the fact that procurement was simplified and virtually infinite. Bezos has an amazing talk in 08 explaining how computing is now a utility.
That meant that hardware costs are now an OPEX expenditure. New applications can be deployed much faster now, there is no need to have planning calls with the data center operations team. Application changes can now happen in a matter of hours.
Although the technology to achieve this is impressive, I’d classify this as a massive progress in terms of process.
Application developers were still running complex applications in the cloud. However the EC2 instances were more ephemeral and we were thinking about new architectures leading to microservices. Most of these applications were SaaS applications and deployment times for changes were now dropping fast.
Present - Microservices
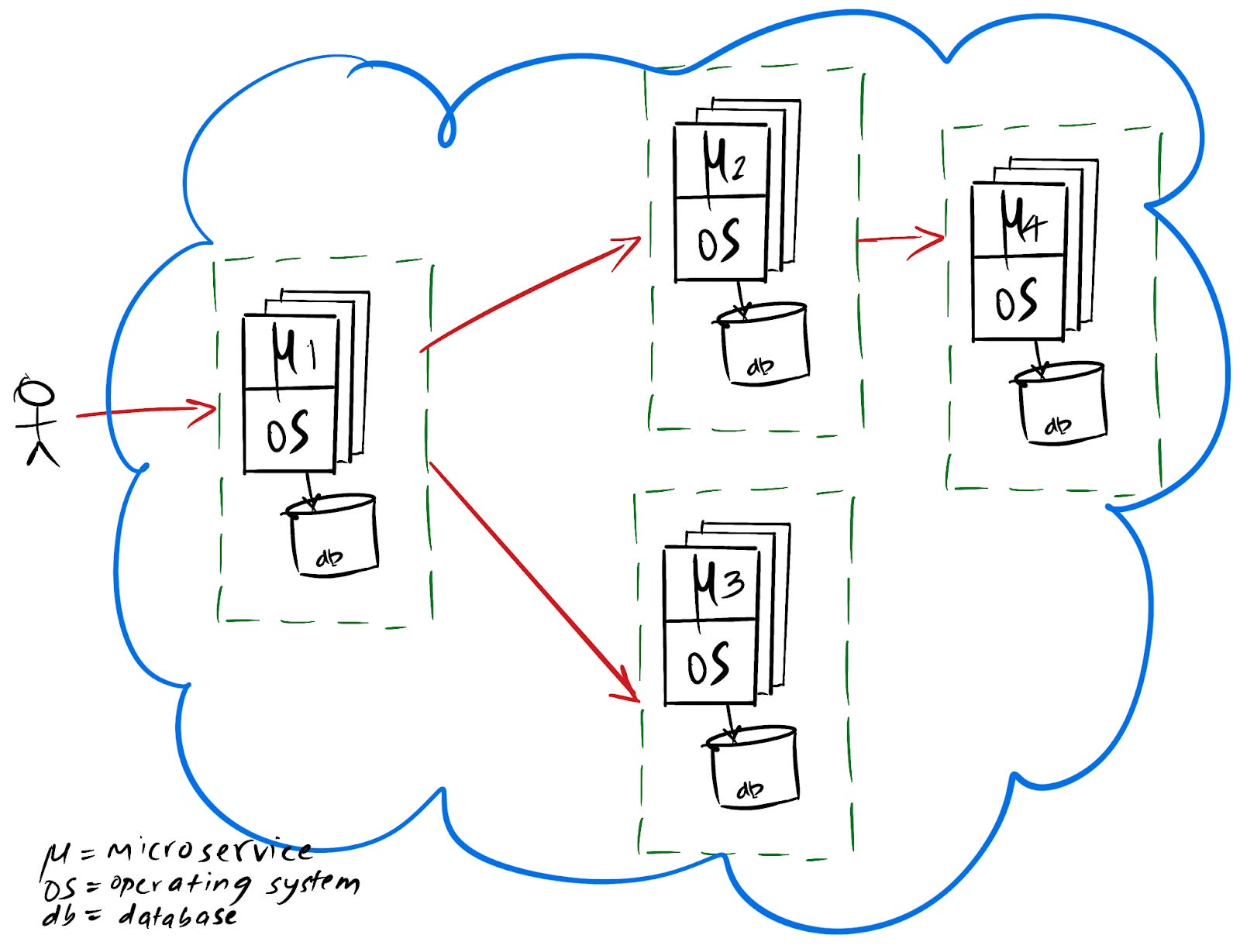
Let’s consider this phase to have started around 2010 to the present day.
Applications needed to be rearchitected so that they can run more efficiently and effectively given the ephemeral nature of the cloud. There was an explosion of options everywhere - nosql storage options optimized for different access patterns, queues, hosted versions of popular open source software, big data. Previous generation applications are now called monoliths, and microservices are the current style for developing applications. A microservice is a smaller cohesive API with certain functional and non-functional requirements. From an application developers and teams perspective, the application domain required is now reduced to a manageable surface area.
Today applications fundamentally have much higher non-functional requirements. The shopping catalogue needs to have millions of items, recommendations need to be fast, a winter storm should not slow down tweets.
We are currently at an advanced maturity stage with Microservices. Architecture patterns are mostly established. Application architecture is now a composition of multiple microservices. As an analogy of microsevices with an operating system process;
The primary process are top level internet or customer facing microservices
The libraries that the the primary process depends on now map to other platform level microservies
Information sharing via IPC has been replaced by various protocols over HTTP.
DevOps started in this period. Infrastructure as code is now common. Deployments now happen multiple times a day and we have rolling upgrades across multiple regions due to enhanced automated testing. Testing is done as part of development processes rather than a separate testing organization or role. Application changes now rollout to customers within minutes. Tooling like feature flags, shards, rolling upgrades help isolating changes for specific scenarios.
Chaos Engineering was also started around this time to be able to test resiliency against failures of infrastructure, network and application dependencies in production! These new testing methodologies can be only applied when applications have been architected in a new way from previous styles.
With growing scale, we’re now building massively distributed applications based on microservices.
Present - Containers
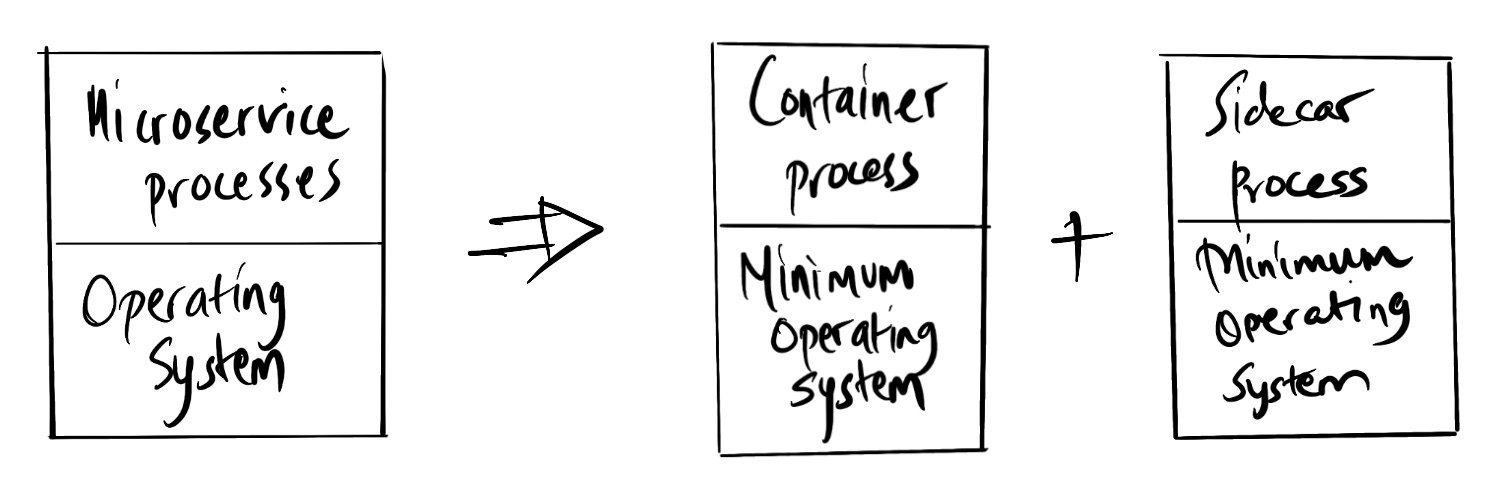
Just as we were getting to grips with microservices, this cool new technology called docker (around 2013) was becoming popular. Docker is based on operating system level virtualization which is much more efficient compared to traditional hypervisors. The base operating system kernel allows multiple isolated userspace containers. The containers only see resources that are exposed to them.
With containers, application developers were able to reduce scope to a single process. This also meant that rather than using full-blown operating systems, smaller compact distributions like alpine became popular. Docker images also used layers (with union filesystems) which made downloads of images extremely fast. How fast a process can start is critical for designing dynamic load balancing. Applications can now start in seconds.
The container ecosystem has also matured. Kubernetes has won the container orchestration battle. AWS and other cloud providers also support containers natively via services like ECS. Cloud-Native is the marketing term for these types of container based services and CNCF is where most of the action is. Luckily most architecture learnings from microservices apply here as well, just that efficiency is higher.
Future - Serverless
Serverless aka Functions-as-a-service became popular when AWS launched lambda. Even though serverless has matured a lot in the 7 years since launch, adoption is still low and we’re still figuring out patterns and best-practices. However I’m stoked with the possibilities. Let’s look at why Serverless is disruptive both from a tech and process point of view with examples from AWS lambda.
On the technology side, the application developer provides the code that will be executed by a managed process based on a certain event. The developer writes code to a language runtime like node, java. The subtle point here is that in earlier programming styles like microservices or containers the process was a complete web server with associated libraries. Now developers need to write code that can parse and return json based on the event integration. Here is an example for writing a serverless lambda that returns a HTTP response. Developers do not need to write complex multi-threading code either because these are now external based on the integration. Not only is this code much simpler author, but also has a reduced risk area for security issues. It’s almost close to the exact business code that you need. Code deployments, including tests can actually happen in seconds now.
Code deployments, including tests can actually happen in seconds now.
Monolith to Microservice decomposition forced developers to reason about what is the scope of a cohesive unit of features for a complex application. Serverless force decomposition into even smaller single features.
The big process disruption is around new billing which is based on per-request or usage. This has been extended from processing (ie lambda) to even persistence like databases. This means that the Operating cost for running experiments now shifts even lower from hundreds of dollars a month to nothing if there is no usage.
We took a long time to build proper logging tools to be able to debug microservices. This takes the problem to a whole new level. I looked at lambda documentation after a long time when researching for this post. The space has matured immensely with custom container images, patterns for state changes (using step functions). DevOps tooling has also caught up to address complexity in integration and management. SAM and similar tooling (terraform pulumi) now make wiring of such complex applications possible via code.
In my opinion, Serverless will become the preferred mechanism to develop server-side applications.
Serverless will become the preferred mechanism to develop server-side applications.
Innovation Waves

Let’s now try and look at common trends from all the eras above and formulate how innovation happens in Waves.
Innovation can be a technology or process shift making something better, faster or cheaper.
Innovations look silly in the beginning. When virtualization was first introduced it was considered too slow for any real applications since it was based on software emulation. Look at where we are now.
I’ve used a major wave for the primary disruption and then smaller waves when there are extensions which further reinforce the disruption.
Innovation causes rapid growth in the new disruptor and based on the market opportunity there can be intense competition and churn. When docker started gaining traction, vmware was very concerned. However since then kubernetes and the cloud providers have seen the most gains from this technology.
Old technology never dies. COBOL is still in demand since someone needs to operate the mainframes which are running critical services.
Innovation changes human behaviour and expectations. Downtime for a few hours was a reasonable expectation a few years back since the developers needed to run a database upgrade. Today’s applications are expected to be online always with fast performance. Slow times by even a few 100ms does have direct impact (https://web.dev/why-speed-matters/) in the bottom line for a company.
Complexity of applications will keep increasing with requirements. New techniques are required to keep maintenance costs low.
Cost goes up with adoption of new technologies. However that cost is a lesser risk compared to getting disrupted by a smaller company with more agility.
Thanks to Bruno Sales and Anonymous for reading drafts of this.